
In the evolving landscape of data science, the choice of database technology plays a crucial role in the effectiveness of data-driven solutions. While traditional relational databases have been the backbone of data storage and retrieval for decades, they are not always the best fit for every type of data or query. As data becomes more interconnected, particularly in areas like social networks, recommendation engines, and fraud detection, the need for more flexible and relationship-oriented data storage has given rise to graph databases. Enrolling in a data science course in Pune can provide the foundational knowledge needed to work with graph databases, along with broader training in data science principles.
Graph databases are designed to handle the complex relationships inherent in connected data. Unlike traditional databases that store data in tables with rows and columns, graph databases store data as nodes, edges, and properties, making them highly effective for use cases where relationships between data points are critical. For data scientists, understanding graph databases can unlock new possibilities for modeling and analyzing data in more intuitive and efficient ways.
What is a Graph Database?
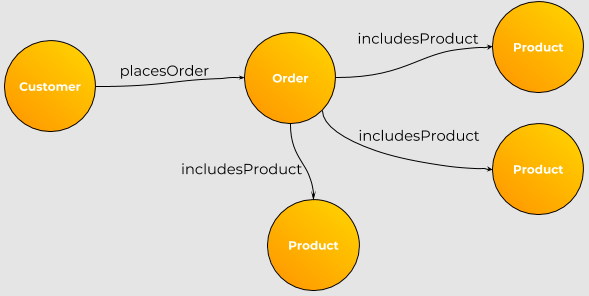
At its core, a graph database is a type of NoSQL database that uses graph theory to store, map, and query relationships between data points. In a graph database, data is represented as nodes (entities) and edges (relationships) connecting these nodes. Each node represents a specific entity, such as a person, product, or event, while each edge represents a relationship between two nodes, such as a friendship, purchase, or interaction. Properties can be assigned to both nodes and edges to describe additional attributes, such as a person’s age or the time of a transaction.
This structure is inherently different from the tabular format of relational databases, where relationships between data points are typically managed using foreign keys and JOIN operations. In contrast, graph databases store relationships as first-class citizens, allowing for more natural and efficient querying of connected data. This makes graph databases particularly well-suited for scenarios where relationships are central to the analysis.
Common Use Cases for Graph Databases
Graph databases have become increasingly popular in various industries, thanks to their ability to model and analyze complex relationships. Some common use cases include:
Social Network Analysis: Social media platforms use graph databases to model users and their relationships, enabling features like friend recommendations, content sharing, and influence analysis. The ability to traverse connections quickly makes graph databases ideal for these applications.
Fraud Detection: In finance, graph databases help detect fraudulent activities by analyzing relationships between transactions, accounts, and entities. By identifying suspicious patterns and connections, financial institutions can prevent and mitigate fraud more effectively.
Recommendation Engines: E-commerce and content platforms use graph databases to power recommendation engines. By analyzing the relationships between users, products, and interactions, these systems can generate personalized recommendations based on a user’s behavior and preferences.
Knowledge Graphs: In industries like healthcare and research, graph databases are used to create knowledge graphs that connect vast amounts of information. These graphs enable advanced queries and insights, such as discovering relationships between diseases, treatments, and outcomes.
Read also: Masterminds and Misfits: The Allure of Heist TV Shows
Challenges and Considerations
While graph databases offer significant advantages, they also come with their own set of challenges. One of the main considerations is the learning curve associated with graph query languages, such as Cypher (used by Neo4j) or Gremlin (used by Apache TinkerPop). These languages differ from SQL and require data scientists to develop new skills.
Another challenge is the complexity of managing and scaling graph databases. As the size and complexity of the graph grow, so does the need for careful planning and optimization to ensure efficient performance. Additionally, while graph databases excel at managing relationships, they may not be the best choice for all types of data, particularly when relationships are not central to the analysis.
Despite these challenges, the growing demand for graph databases is driving increased interest in this technology among data scientists. As more organizations recognize the value of connected data, the ability to work with graph databases is becoming an important skill in the data scientist’s toolkit.
Learning Graph Databases: A Path Forward
For those looking to deepen their understanding of graph databases and their applications, formal education and hands-on experience are key. Such courses often cover essential topics like data modeling, query languages, and advanced analytics, all of which are critical for effectively using graph databases.
Moreover, for individuals seeking to learn in a vibrant educational environment, data scientist course is an excellent option. Pune is known for its strong academic institutions and thriving tech community, making it an ideal location for aspiring data scientists. Courses offered in Pune typically combine theoretical instruction with practical experience, ensuring that students are well-prepared to tackle real-world data challenges.
Conclusion
Graph databases represent a powerful tool for data scientists working with connected data. Their ability to efficiently model and analyze relationships opens up new possibilities for solving complex problems in various domains. As the demand for graph databases continues to grow, so too does the need for data scientists who can leverage this technology effectively.
For data scientists looking to expand their skill set and stay ahead of industry trends, understanding graph databases is becoming increasingly important. Whether through formal education, such as a data scientist course, or practical experience gained from a data science course in Pune, there are ample opportunities to learn and grow in this exciting field. By mastering graph databases, data scientists can unlock new insights, drive innovation, and make a meaningful impact in their organizations.
Contact Us:
ExcelR – Data Science, Data Analyst Course Training
Address: 1st Floor, East Court Phoenix Market City, F-02, Clover Park, Viman Nagar, Pune, Maharashtra 411014
Phone Number: 096997 53213
Email Id: Enquiry@excelr.com



